
Tableau sales will exceed $40M in 2010 (and they planning to employ 300+ by end of 2011!), which is almost 20% of Qliktech sales in 2010. My guesstimate (if anybody has better data, please comment on it) that Spotfire's sales in 2010 are about $80M. Qliktech's market capitalization exceeded recently $2B, more than twice of Microstrategy ($930M as of today) Cap!
I recently noticed that Gartner trying to coin the new catch phrase because old (referring to BI, which never worked because intelligence is attribute of humans and not attribute of businesses) does not work. Now they are saying that for last 20+ years when they talked about business intelligence (BI) they meant an intelligent business. I think this is confusing because (at least in USA) business is all about profit and Chief Business Intelligent Dr. Karl Marx will agree with that. I respect the phrase "Profitable Business" but "Intelligent Business" reminds me the old phrase "Crocodile tears". Gartner also saying that BI projects should be treated as a "cultural transformation" which reminds me a road paved with good intentions.
I also noticed the huge attention paid by Forrester to Advanced Data Visualization and probably for 4 good reasons (I have the different reasoning, but I am not part of Forrester) :
- data visualization can fit much more (tens of thousands) data points into one screen or page compare with numerical information and datagrid ( hundreds datapoints per screen);
- ability to visually drilldown and zoom through interactive and synchronized charts;
- ability to convey a story behind the data to a wider audience through data visualization.
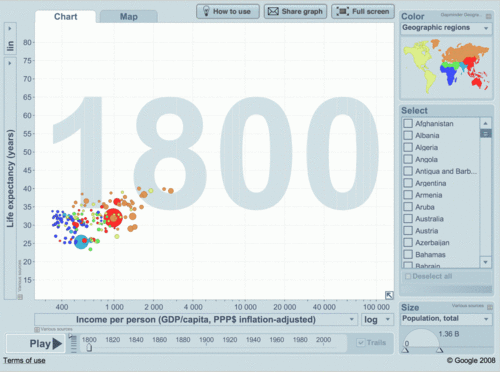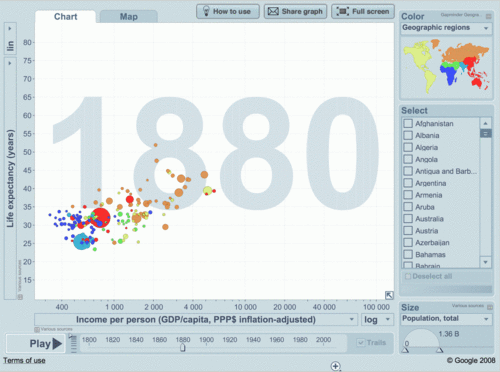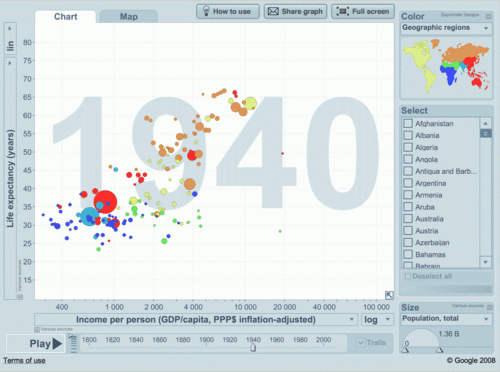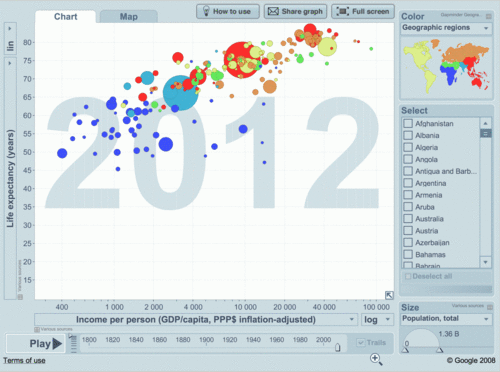
- analysts and decision makers cannot see patterns (and in many cases also trends and outliers) in data without data visualization, like 37+ years old example, known as Anscombe’s quartet, which comprises four datasets that have identical simple statistical properties, yet appear very different when visualized. They were constructed by F.J. Anscombe to demonstrate the importance of Data Visualization (DV):
| I | II | III | IV | ||||
|---|---|---|---|---|---|---|---|
| x | y | x | y | x | y | x | y |
| 10.0 | 8.04 | 10.0 | 9.14 | 10.0 | 7.46 | 8.0 | 6.58 |
| 8.0 | 6.95 | 8.0 | 8.14 | 8.0 | 6.77 | 8.0 | 5.76 |
| 13.0 | 7.58 | 13.0 | 8.74 | 13.0 | 12.74 | 8.0 | 7.71 |
| 9.0 | 8.81 | 9.0 | 8.77 | 9.0 | 7.11 | 8.0 | 8.84 |
| 11.0 | 8.33 | 11.0 | 9.26 | 11.0 | 7.81 | 8.0 | 8.47 |
| 14.0 | 9.96 | 14.0 | 8.10 | 14.0 | 8.84 | 8.0 | 7.04 |
| 6.0 | 7.24 | 6.0 | 6.13 | 6.0 | 6.08 | 8.0 | 5.25 |
| 4.0 | 4.26 | 4.0 | 3.10 | 4.0 | 5.39 | 19.0 | 12.50 |
| 12.0 | 10.84 | 12.0 | 9.13 | 12.0 | 8.15 | 8.0 | 5.56 |
| 7.0 | 4.82 | 7.0 | 7.26 | 7.0 | 6.42 | 8.0 | 7.91 |
| 5.0 | 5.68 | 5.0 | 4.74 | 5.0 | 5.73 | 8.0 | 6.89 |

In 2nd half of 2010 all 3 DV leaders released new versions of their beautiful software: Qlikview, Spotfire and Tableau. Visokio's Omniscope 2.6 will be available soon and I am waiting for it since June 2010... In 2010 Microsoft, IBM, SAP, SAS, Oracle, Microstrategy etc. all trying hard to catch up with DV leaders and I wish to all of them the best of luck in 2011. Here is a list of some other things I still remember from 2010:
- Microsoft officially declared that it prefers BISM over OLAP and will invest into their future accordingly. I am very disappointed with Microsoft, because it did not include BIDS (Business Intelligence Development Studio) into Visual Studio 2010. Even with release of supercool and free PowerPivot it is likely now that Microsoft will not be a leader in DV (Data Visualization), given it discontinued ProClarity and PerformancePoint and considering ugliness of SharePoint. Project Crescent (new visualization "experience" from Microsoft) was announced 6 weeks ago, but still not too many details about it, except that it mostly done with Silverlight 5 and Community Technology Preview will be available in 1st half of 2011.
- SAP bought Sybase, released new version 4.0 of Business Objects and HANA "analytic appliance"
- IBM bought Netezza and released Cognos 10.
- Oracle released OBIEE 11g with ROLAP and MOLAP unified
- Microstrategy released its version 9 Released 3 with much faster performance, integration with ESRI and support for web-serviced data
- EMC bought Greenplum and started new DCD (Data Computing Division), which is obvious attempt to join BI and DV market
- Panorama released NovaView for PowerPivot, which is natively connecting to the PowerPivot in-memory models.
- Actuate's BIRT was downloaded 10 million times (!) and has over a million (!) BIRT developers
- Panopticon 5.7 was released recently (on 11/22/10) and adds the ability to display real-time streaming data.
David Raab, one of my favorite DV and BI gurus, published on his blog the interesting comparison of some leading DV tools. According to David' scenario, one of possible ranking of DV Tools can be like that: Tableau is 1st than Advizor (version 5.6 available since June 2010), Spotfire and Qlikview (seems to me David implied that order). In my recent DV comparison "my scenario" gave a different ranking: Qlikview is slightly ahead, while Spotfire and Tableau are sharing 2nd place (but very competitive to Qlikview) and Microsoft is distant 4th place, but it is possible that David knows something, which I don't...
In addition to David, I want to thank Boris Evelson, Mark Smith, Prof. Shneiderman, Prof. Rosling, Curt Monash, Stephen Few and others for their publications, articles, blogs and demos dedicated to Data Visualization in 2010 and before.
Permalink: http://apandre.wordpress.com/2010/12/25/hny2011/




























")





{kind=link}
{kind=link}
{kind=link}
{kind=link}